- Record: found
- Abstract: found
- Article: found
GSVD Comparison of Patient-Matched Normal and Tumor aCGH Profiles Reveals Global Copy-Number Alterations Predicting Glioblastoma Multiforme Survival

Read this article at
Abstract
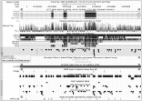
Despite recent large-scale profiling efforts, the best prognostic predictor of glioblastoma
multiforme (GBM) remains the patient's age at diagnosis. We describe a global pattern
of tumor-exclusive co-occurring copy-number alterations (CNAs) that is correlated,
possibly coordinated with GBM patients' survival and response to chemotherapy. The
pattern is revealed by GSVD comparison of patient-matched but probe-independent GBM
and normal aCGH datasets from The Cancer Genome Atlas (TCGA). We find that, first,
the GSVD, formulated as a framework for comparatively modeling two composite datasets,
removes from the pattern copy-number variations (CNVs) that occur in the normal human
genome (e.g., female-specific X chromosome amplification) and experimental variations
(e.g., in tissue batch, genomic center, hybridization date and scanner), without a-priori
knowledge of these variations. Second, the pattern includes most known GBM-associated
changes in chromosome numbers and focal CNAs, as well as several previously unreported
CNAs in
 3% of the patients. These include the biochemically putative drug target, cell cycle-regulated
serine/threonine kinase-encoding
TLK2, the cyclin E1-encoding
CCNE1, and the Rb-binding histone demethylase-encoding
KDM5A. Third, the pattern provides a better prognostic predictor than the chromosome numbers
or any one focal CNA that it identifies, suggesting that the GBM survival phenotype
is an outcome of its global genotype. The pattern is independent of age, and combined
with age, makes a better predictor than age alone. GSVD comparison of matched profiles
of a larger set of TCGA patients, inclusive of the initial set, confirms the global
pattern. GSVD classification of the GBM profiles of an independent set of patients
validates the prognostic contribution of the pattern.
3% of the patients. These include the biochemically putative drug target, cell cycle-regulated
serine/threonine kinase-encoding
TLK2, the cyclin E1-encoding
CCNE1, and the Rb-binding histone demethylase-encoding
KDM5A. Third, the pattern provides a better prognostic predictor than the chromosome numbers
or any one focal CNA that it identifies, suggesting that the GBM survival phenotype
is an outcome of its global genotype. The pattern is independent of age, and combined
with age, makes a better predictor than age alone. GSVD comparison of matched profiles
of a larger set of TCGA patients, inclusive of the initial set, confirms the global
pattern. GSVD classification of the GBM profiles of an independent set of patients
validates the prognostic contribution of the pattern.
Related collections
Most cited references27
- Record: found
- Abstract: found
- Article: not found
Systematic determination of genetic network architecture.
- Record: found
- Abstract: found
- Article: found
The UCSC Genome Browser database: update 2011
- Record: found
- Abstract: found
- Article: not found