- Record: found
- Abstract: found
- Article: found
On the Analysis of Genome-Wide Association Studies in Family-Based Designs: A Universal, Robust Analysis Approach and an Application to Four Genome-Wide Association Studies
Read this article at
Abstract
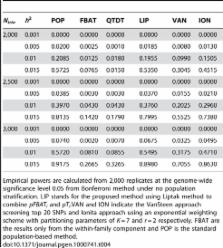
For genome-wide association studies in family-based designs, we propose a new, universally applicable approach. The new test statistic exploits all available information about the association, while, by virtue of its design, it maintains the same robustness against population admixture as traditional family-based approaches that are based exclusively on the within-family information. The approach is suitable for the analysis of almost any trait type, e.g. binary, continuous, time-to-onset, multivariate, etc., and combinations of those. We use simulation studies to verify all theoretically derived properties of the approach, estimate its power, and compare it with other standard approaches. We illustrate the practical implications of the new analysis method by an application to a lung-function phenotype, forced expiratory volume in one second (FEV1) in 4 genome-wide association studies.
Author Summary
In genome-wide association studies, the multiple testing problem and confounding due to population stratification have been intractable issues. Family-based designs have considered only the transmission of genotypes from founder to nonfounder to prevent sensitivity to the population stratification, which leads to the loss of information. Here we propose a novel analysis approach that combines mutually independent FBAT and screening statistics in a robust way. The proposed method is more powerful than any other, while it preserves the complete robustness of family-based association tests, which only achieves much smaller power level. Furthermore, the proposed method is virtually as powerful as population-based approaches/designs, even in the absence of population stratification. By nature of the proposed method, it is always robust as long as FBAT is valid, and the proposed method achieves the optimal efficiency if our linear model for screening test reasonably explains the observed data in terms of covariance structure and population admixture. We illustrate the practical relevance of the approach by an application in 4 genome-wide association studies.
Related collections
Most cited references22
- Record: found
- Abstract: found
- Article: not found
A general test of association for quantitative traits in nuclear families.
- Record: found
- Abstract: found
- Article: not found
Implementing a unified approach to family-based tests of association.
- Record: found
- Abstract: found
- Article: not found