- Record: found
- Abstract: found
- Article: found
The influence of macroinvertebrate abundance on the assessment of freshwater quality in The Netherlands
Read this article at
Abstract
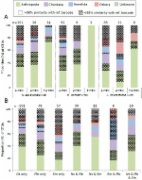
The use of molecular tools for the detection and identification of invertebrate species enables the development of more easily standardisable inventories of biological elements for water quality assessments, as it circumvents human-based bias and errors in species identifications. Current Ecological Quality Ratio (EQR) assessments methods, however, often rely on abundance data. Translating metabarcoding sequence data into biomass or specimen abundances has proven difficult, as PCR amplification bias due to primer mismatching often provides skewed proportions of read abundances. While some potential solutions have been proposed in previous research, we instead looked at the necessity of abundance data in EQR assessments. In this study, we used historical monitoring data from natural (lakes, rivers and streams) and artificial (ditches and canals) water bodies to assess the impact of species abundances on the EQR scores for macroinvertebrates in the Water Framework Directive (WFD) monitoring programme of The Netherlands. By removing all the abundance data from the taxon observations, we simulated presence/absence-based monitoring, for which EQRs were calculated according to traditional methods. Our results showed a strong correlation between abundance-based and presence/absence-based EQRs. EQR scores were generally higher without abundances (75.8% of all samples), which resulted in 9.1% of samples being assigned to a higher quality class. The majority of the samples (89.7%) were assigned to the same quality class in both cases. These results are valuable for the incorporation of presence/absence metabarcoding data into water quality assessment methodology, potentially eliminating the need to translate metabarcoding data into biomass or absolute specimen counts for EQR assessments.
Related collections
Most cited references26
- Record: found
- Abstract: found
- Article: not found
Quantifying microbial communities with 454 pyrosequencing: does read abundance count?

- Record: found
- Abstract: found
- Article: found