- Record: found
- Abstract: found
- Article: not found
Artificial intelligence and machine learning approaches for drug design: challenges and opportunities for the pharmaceutical industries
Read this article at

Abstract
Abstract
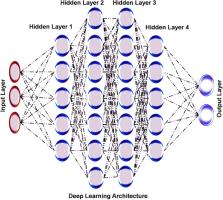
The global spread of COVID-19 has raised the importance of pharmaceutical drug development as intractable and hot research. Developing new drug molecules to overcome any disease is a costly and lengthy process, but the process continues uninterrupted. The critical point to consider the drug design is to use the available data resources and to find new and novel leads. Once the drug target is identified, several interdisciplinary areas work together with artificial intelligence (AI) and machine learning (ML) methods to get enriched drugs. These AI and ML methods are applied in every step of the computer-aided drug design, and integrating these AI and ML methods results in a high success rate of hit compounds. In addition, this AI and ML integration with high-dimension data and its powerful capacity have taken a step forward. Clinical trials output prediction through the AI/ML integrated models could further decrease the clinical trials cost by also improving the success rate. Through this review, we discuss the backend of AI and ML methods in supporting the computer-aided drug design, along with its challenge and opportunity for the pharmaceutical industry.

Related collections
Most cited references184

- Record: found
- Abstract: found
- Article: found
SwissADME: a free web tool to evaluate pharmacokinetics, drug-likeness and medicinal chemistry friendliness of small molecules
- Record: found
- Abstract: found
- Article: not found
The Genotype-Tissue Expression (GTEx) project.

- Record: found
- Abstract: found
- Article: found