- Record: found
- Abstract: found
- Article: found
Propensity score analysis with partially observed covariates: How should multiple imputation be used?
Abstract
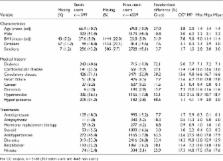
Inverse probability of treatment weighting is a popular propensity score-based approach to estimate marginal treatment effects in observational studies at risk of confounding bias. A major issue when estimating the propensity score is the presence of partially observed covariates. Multiple imputation is a natural approach to handle missing data on covariates: covariates are imputed and a propensity score analysis is performed in each imputed dataset to estimate the treatment effect. The treatment effect estimates from each imputed dataset are then combined to obtain an overall estimate. We call this method MIte. However, an alternative approach has been proposed, in which the propensity scores are combined across the imputed datasets (MIps). Therefore, there are remaining uncertainties about how to implement multiple imputation for propensity score analysis: (a) should we apply Rubin’s rules to the inverse probability of treatment weighting treatment effect estimates or to the propensity score estimates themselves? (b) does the outcome have to be included in the imputation model? (c) how should we estimate the variance of the inverse probability of treatment weighting estimator after multiple imputation? We studied the consistency and balancing properties of the MIte and MIps estimators and performed a simulation study to empirically assess their performance for the analysis of a binary outcome. We also compared the performance of these methods to complete case analysis and the missingness pattern approach, which uses a different propensity score model for each pattern of missingness, and a third multiple imputation approach in which the propensity score parameters are combined rather than the propensity scores themselves (MIpar). Under a missing at random mechanism, complete case and missingness pattern analyses were biased in most cases for estimating the marginal treatment effect, whereas multiple imputation approaches were approximately unbiased as long as the outcome was included in the imputation model. Only MIte was unbiased in all the studied scenarios and Rubin’s rules provided good variance estimates for MIte. The propensity score estimated in the MIte approach showed good balancing properties. In conclusion, when using multiple imputation in the inverse probability of treatment weighting context, MIte with the outcome included in the imputation model is the preferred approach.
Related collections
Most cited references30
- Record: found
- Abstract: found
- Article: not found
Randomized, Controlled Trials, Observational Studies, and the Hierarchy of Research Designs
- Record: found
- Abstract: not found
- Book: not found
Causal Inference for Statistics, Social, and Biomedical Sciences
- Record: found
- Abstract: found
- Article: not found