
INTRODUCTION
Currently, blind and visually impaired persons are switching from standard writing and reading in Braille to using computers with user-friendly applications ( Montazerin et al., 2022). Hand gestures have an eminent role in assistive technology for individuals with low vision, where a good user interaction model is of great significance. Certain applications and devices in this domain can significantly benefit from an intuitive, agile, and natural communication system that uses hand gestures ( Xu et al., 2023). In the computer vision (CV) domain, gesture language recognition has gained special attention to precisely detect gesture movement and understand the sense of gesture language for machines or communicators. The detection of gesture language action has enormous application in robot perception, enhancing people with speech impairments and improvising nonverbal data transfer ( Rashid et al., 2022). As gesture language movement is usually very fast, the usage of conventional frame cameras presents greater difficulties, such as computational complexity and blur and overlap ( Shokat et al., 2021). Gesture customization is significant for the many motor-impaired persons with heavy movement limitations who are unable to do some gestures described by the manufacturer of the system. In that mechanism, the small training set made individually for all users would allow the system to be fully utilized ( Jyothsna et al., 2022). The small training set in the gesture recognition approach was previously inspected, for example, for the spiking neural network (NN) method and hand gesture recognition (HGR) with a deep sensor concept.
Machine vision-related gesture recognition does not need physical interference of the user nor the use of specialized equipment or additional sensors ( Shen et al., 2023). Rather, it should be trained with loads of image datasets for gaining a highly precise recognition method and attain precise HGR ( Padmavathi, 2021). Previous gesture detection approaches are based on the manual extraction of gesture features (e.g., texture, shape, and color) for gesture detection, but these techniques depend on the knowledge of experts and cannot resolve the issue of complicated images with skin-like backgrounds ( De Fazio et al., 2022). With the progress of deep learning (DL) methods, numerous researchers have used advanced DL approaches for gesture detection. Comparatively, using DL approaches for gesture detection has features of high accuracy, self-extraction of features, greater efficiency, and strong adaptability and robustness for managing more data ( Muneeb et al., 2023). DL methods such as convolution neural networks (CNN) and long short-term memory (LSTM) are better choices for classifying and detecting a sequence of gestures. However, the methods operate under the assumption that the start and end places of the gesture series are available before all individual gestures are detected ( Hegde et al., 2022).
This article presents a robust gesture recognition and classification using growth optimizer with deep stacked autoencoder (RGRC-GODSAE) model for visually impaired persons. The goal of the RGRC-GODSAE technique lies in the accurate recognition and classification of gestures to assist visually impaired persons. The RGRC-GODSAE technique follows the Gabor filter (GF) approach at the initial stage to remove noise. In addition, the RGRC-GODSAE technique uses the ShuffleNet model as a feature extractor and the GO algorithm as a hyperparameter optimizer. Finally, the deep stacked autoencoder (DSAE) model is exploited for the automated recognition and classification of gestures. The experimental validation of the RGRC-GODSAE technique is carried out on the benchmark dataset.
LITERATURE REVIEW
Gaidhani et al. (2022) introduced a CNN method, as it has more precision compared with other techniques. Python is a computer program written in the programming language that can be utilized for model training, depending on the CNN mechanism. Using Indian sign language, the input with a preexisting dataset created is compared so that the method can understand hand gestures. Users could detect the signs presented by transforming sign language into the text as outputs by sign language interpreters. Miah et al. (2023) modeled a multistage spatial attention-related NN for HGC to solve the difficulties. This method has phases; the author implemented a spatial attention module and feature extractors utilizing self-attention from the original data. Later, the author explored attributes connected with the original data to gain modality feature embedding. Likewise, the author made an attention map and feature vector in the second phase with the self-attention technique and feature extraction architecture. Raja et al. (2019) indicated the implementation and model of a facial detection system for blind people with image processing. The developed device has programmed raspberry pi hardware. The data are given to the device in the image format. The imageries captured are preprocessed in the raspberry pi module utilizing the k-nearest neighbor (KNN) approach, the face is detected, and the name is given into text-to-speech conversion modules.
Hegde et al. (2021) presented a user-friendly, low-cost, portable, low-power, robust, and reliable solution for smooth navigation. This study is mainly for blind persons. It has an in-built sensor that spreads ultrasonic waves in an individual’s direction by scanning 5-6 m of range. As soon as the obstacle can be identified, the sensor finds it and transfers it to the device that generated an automatic voice in the earphone linked to one’s ear. Yoo et al. (2022) modeled a hybrid HGR that integrates a vision-based gesture system and an inertial measurement unit (IMU)-related motion capture mechanism. First, vision-related commands and IMU-based commands are classified as drone operation commands. Second, IMU-related control command is mapped intuitively to enable the drone to go in a similar direction through predicted orientation sensed by thumb-mounted micro-IMU. In Subburaj et al. (2023), human gestures are classified utilizing data gathered from curved piezoelectric sensors, which include coughing, elbow movement, wrist bending, neck bending, and wrist turning. Machine learning (ML) methods enabled with K-mer are optimized and developed for performing HGR from the obtained data. Three ML methods, namely, k-NN, SVM, and RF, are analyzed and executed with K-mer.
Chen et al. (2021) modeled a wearable navigation gadget for blind people by compiling the semantic visual of the powerful mobile computing environment and SLAM (Simultaneous Localization and Mapping). The author concentrated on the integration of SLAM technology with the abstraction of semantic data from the atmosphere. In Zakariah et al. (2022), they devised a system that would utilize the visual hand data depending on Arabic Sign Language and combined this visual dataset with text data. Different data augmentation and preprocessing methods were implemented in the images. The experiments were conducted with different pretrained methods on the given data. The EfficientNetB4 method was the better best fit for the case.
MATERIALS AND METHODS
In this article, we have introduced a new RGRC-GODSAE technique for effectual recognition and classification of gestures to aid visually impaired persons. Figure 1 demonstrates the workflow of the RGRC-GODSAE system. The main aim of the RGRC-GODSAE technique lies in the accurate recognition and classification of gestures to assist visually impaired persons. The RGRC-GODSAE technique comprises several subprocesses, namely, GF-based noise elimination, ShuffleNet feature extractor, GO-based hyperparameter tuning, and DSAE-based gesture recognition.

Workflow of RGRC-GODSAE system. RGRC-GODSAE, robust gesture recognition and classification using growth optimizer with deep stacked autoencoder.
Noise elimination using GF approach
To eliminate noise, the GF approach is used. In image processing, the GF method is broadly used to analyze image orientation and texture ( Lee et al., 2023). It depends on a family of bandpass filters called the GF method that can be utilized for abstracting attributes from images through the convolution of the image with a group of GF methods of various frequencies and orientations. It refers to a complex sinusoidal wave, and a Gaussian function modulates it. It can be defined in the frequency and spatial domains, which allows it to inspect an image in both domains concurrently. The two parameters of the filter are altered to control its orientation and frequency.
ShuffleNet feature extractor
For effectual derivation of the feature vectors, the ShuffleNet model is used. Among MobileNetV2, ShuffleNetV1, and Xception, ShuffleNetV2 has the fastest speed and the highest accuracy ( Fu et al., 2023). It primarily exploits two new operations, channel shuffle and pointwise group convolution, that considerably lessen the computational cost without affecting detection performance. Group convolution (GC) was initially applied in AlexNet to distribute the network through two graphics processing units (GPUs), which showed its efficiency in ResNeXt. The conventional convolution (CC) adopts a channel-dense connection that implements a convolution function on all the channels of the input feature. For CC, the height and width of the kernels are K, and C signifies the number of input channels; when the amount of the kernel denotes N, then the amount of output channels is also N:
For GC, the channel of input features was separated into G groups so that the amount of kernel can be C/G; the outcomes from the G group were concatenated into large feature output of the N channels:
From the aforementioned formula, we could say that the amount of parameters in GC is much smaller than in CC. However, GC causes the issue that dissimilar groups might no longer share data. Thus, ShuffleNet implements a channel shuffle process on the output feature, so that data can be circulated over various groups without increasing the computational cost. In ShuffleNetV2 unit 1, a channel split can be initially executed on the input feature map that can be evenly divided into dual branches. The right branch undergoes three convolutional functions, while the left branch remains the same. Both branches are concatenated to fuse the features once the convolution is finished. In conclusion, Channel Shuffle transmits data between various groups. In ShuffleNetsV2 unit 2, the channel was not separated in the early stages, and the feature map can be inputted directly toward both branches. These two branches exploit 3 × 3 deep convolutional layers for minimizing the dimension of the feature map. Later, the concatenation function can be implemented on the output of both branches.
Hyperparameter tuning using GO algorithm
In this work, the GO algorithm is utilized for optimal hyperparameter selection of the ShuffleNet model. GO algorithm assumes that persons train and reflect as it is developed in society ( Fatani et al., 2023). During the learning model, the data have been gathered in the environment, but the reflection purpose for examining the limitations enhance the learning process.
Generally, the GO begins with utilizing Eq. (3) for generating the population X that represents the solutions for the testing problem:
whereas r refers to the arbitrary value and the restrictions of searching the area of the problems can be signified utilizing U and L. N denotes the entire count of solutions in X. Later, X can be separated into three parts based on the parameters called P 1 = 5. A primary part includes leaders and elites (different in 2 to P 1). The second part has the middle level (i.e., from P 1+1 to N− P 1), and the tertiary part comprises the bottom level (i.e., N− P 1+1 and N), but an optimum solution was the leader of the upper level.
By challenging the disparities among people, inspecting the reasons for individual differences, and learning based on them, individuals are significantly assisted in their development. The learning stage of GO mimics four key gaps, which can be in the form:
in which, X b, X bt , and X w are simply the best, better, and worse solutions, correspondingly; besides, X r 1 and X r 2 denote two arbitrary solutions. G k( k = 1, 2, 3, 4) signifies the gap utilized for improving skills learned and reducing the variance among them. Besides, to reflect the difference among groups, the parameter termed as a learning factor (LF) was executed, and its formula can be provided as:
Next, the individual considers his learning skill utilizing the parameter ( SF i ):
whereas GR max and GR i indicate the maximal growth resistance of X and the development of X i correspondingly.
Based on the data gathered in LF k and SF i , every X i is to obtain novel knowledge in the solution appropriate to all the gaps in G k utilizing the knowledge acquisition ( KA) that can be determined as:
Then, the solution X i enhanced their data utilizing the following equation:
The quality of the upgrade form of X i was calculated and related to the preceding one to define if there is a major difference between them:
in which r 2 denotes the arbitrary number, and P 2 = 0.001 signifies the probability of retention. ind( i) represents the ranking of X i dependent upon ascending order X utilizing the fitness value.
The solution can progress its capability to reflect on the data that can be learned, representing that X can recognize their entire region of weakness and maintain their data. It must implement the unwanted elements of a successful X, but recollects its outstanding qualities. Once the lesson of a particular feature cannot be fixed, the previous data can be unrestricted and systematic learning must restart. Equations (10) and (11) are employed for mathematical formulas during this procedure:
whereas r 3, r 4, and r 5 represent the random values; X R denotes the solution determined as the top P 1+1 results in X; and AP implies the attenuation aspect dependent on function estimation PE and entire count of functions estimations max. Later the whole reflection phase, X j , can estimate its growth related to the learning stage. Thus, Eq. (9) is also executed for achieving this task.
The GO method makes extraction of a fitness function (FF) to get better classification performance. It ascertains a positive integer that specifies the candidate solution’s better performance. Here the minimal classifier error rate is the FF, as given in Eq. (12):
Gesture classification using DSAE model
At the final stage, the DSAE model is exploited for accurate detection and classification of gestures. AE is a DNN used for learning a compressed representation of an input dataset ( Samee et al., 2022). The AE was trained to remove irrelevant noise, and data and its output were an encoding form for the sequence of data. The AE includes encoder and decoder models. The encoder maps the input variable into compressed format, whereas the decoder tries to reverse the mapping for regenerating input. Using the scaled conjugate gradient algorithm, SAE was trained in an unsupervised way in this study, with 1000 training epochs. The AE is used for ignoring the irrelevant ones and extracting the hidden features. The input variable was fed into the AE and the neurons in the hidden layer were attuned to be lesser than the input size. By including a regularization for the activation of neurons to the cost function we combined sparsity in the AE. The cost function was the MSE function altered to have two terms as shown in Eq. (13): the sparsity regularization, Ω-sparsity, and the weight regularization, Ω-weights. The weight regularization term avoids the value of neuron weight from increasing, which accordingly minimizes the sparsity regularizer. The sparsity regularizer restricts the outputs from the neuron to be lower, which allows the AE to determine representations from a smaller part of the training sample. Equations (14) and (15) illustrated the mathematical representation of Ω-sparsity and Ω-weights, correspondingly:
where N indicates the number of input parameters in the training dataset, M denotes the number of instances in the training set, X represents the estimate of the training instance, x denotes a training sample, and β indicates coefficients of the weight regularizer and sparsity, correspondingly:
where w denotes the weight matrix and L signifies the size of hidden layers:
where KL signifies the Kullback–Leibler divergence value between ρ j and ˆρi.ˆρi signifies the average activation of neuron i, and ρ characterizes the desired activation. Figure 2 represents the infrastructure of the SAE method.

We have applied an SAE, in two phases, by training the initial AE, AE-1, on the input variable, and utilizing the feature abstracted from AE-1 as inputted to the next phase, AE-2. The transfer function utilized for the initial encoder (Encoder−1) was the positive saturating linear transfer, whereas the ordinary linear transfer function can be utilized for the initial decoder (Decoder−1). Positive saturating linear was applied in encoder and decoder models as shown in Eq. (16). In this work, each input variable, M = 36, N = 540, was fed into AE-1. The amount of features derived from stage 1 was 10 features, hence the amount of inputs to AE-2 was = 10, N = 540. Five relevant features are extracted from AE-2 and applied in the prediction stage. We have implemented a lot of research to set the value of the learning parameter and the recorded value was the one that produced the minimal root mean squared error (RMSE) for the anticipated value of the response variable.
RESULTS AND DISCUSSION
In this section, the experimental validation of the RGRC-GODSAE method can be examined on the dataset, comprising several classes, namely, Wrist watch (Cl-1), Dog (Cl-2), Stop sign (Cl-3), Person (Cl-4), Stairs (Cl-5), Chair (Cl-6), Table (Cl-7), and Washroom (Cl-8). The dataset shows 1600 samples with 8 classes, as shown in Table 1. For experimental validation, 80:20 and 70:30 of training/testing dataset is used.
Details of database.
| Class | Labels | No. of samples |
|---|---|---|
| Wrist watch | Cl-1 | 200 |
| Dog | Cl-2 | 200 |
| Stop sign | Cl-3 | 200 |
| Person | Cl-4 | 200 |
| Stairs | Cl-5 | 200 |
| Chair | Cl-6 | 200 |
| Table | Cl-7 | 200 |
| Washroom | Cl-8 | 200 |
| Total number of samples | 1600 |
In Figure 3, the confusion matrices of the RGRC-GODSAE method are examined in detail. The results indicate that the RGRC-GODSAE technique recognizes eight different class labels.

Confusion matrices of RGRC-GODSAE approach (a, b) 80:20 of TRP/TSP and (c, d) 70:30 of TRP/TSP. RGRC-GODSAE, robust gesture recognition and classification using growth optimizer with deep stacked autoencoder.
In Table 2 and Figure 4, the gesture recognition outcomes of the RGRC-GODSAE method under 80:20 of TRP/TSP are reported. The experimental values recognized that the RGRC-GODSAE technique accurately detects all the classes. For instance, on 80% of TRP, the RGRC-GODSAE technique attains an average accu y of 99.77%, prec n of 99.08%, recall of 99.06%, F score of 99.07%, and G measure of 99.07%. Additionally, on 20% of TSP, the RGRC-GODSAE approach attains average accu y of 99.61%, prec n of 98.50%, recall of 98.56%, F score of 98.50%, and G measure of 98.52%.
Gesture recognition outcome of RGRC-GODSAE approach on 80:20 of TRP/TSP.
| Class | Accuracy | Precision | Recall | F-Score | G-Measure |
|---|---|---|---|---|---|
| Training phase (80%) | |||||
| Wrist watch (Cl-1) | 99.84 | 98.84 | 100.00 | 99.42 | 99.42 |
| Dog (Cl-2) | 99.69 | 99.36 | 98.11 | 98.73 | 98.74 |
| Stop sign (Cl-3) | 99.53 | 98.14 | 98.14 | 98.14 | 98.14 |
| Person (Cl-4) | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| Stairs (Cl-5) | 99.92 | 99.38 | 100.00 | 99.69 | 99.69 |
| Chair (Cl-6) | 99.53 | 97.53 | 98.75 | 98.14 | 98.14 |
| Table (Cl-7) | 99.92 | 100.00 | 99.37 | 99.68 | 99.68 |
| Washroom (Cl-8) | 99.69 | 99.36 | 98.11 | 98.73 | 98.74 |
| Average | 99.77 | 99.08 | 99.06 | 99.07 | 99.07 |
| Testing phase (20%) | |||||
| Wrist watch (Cl-1) | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| Dog (Cl-2) | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| Stop sign (Cl-3) | 99.69 | 97.50 | 100.00 | 98.73 | 98.74 |
| Person (Cl-4) | 99.38 | 100.00 | 95.65 | 97.78 | 97.80 |
| Stairs (Cl-5) | 99.69 | 97.62 | 100.00 | 98.80 | 98.80 |
| Chair (Cl-6) | 99.69 | 97.56 | 100.00 | 98.77 | 98.77 |
| Table (Cl-7) | 99.06 | 100.00 | 92.86 | 96.30 | 96.36 |
| Washroom (Cl-8) | 99.38 | 95.35 | 100.00 | 97.62 | 97.65 |
| Average | 99.61 | 98.50 | 98.56 | 98.50 | 98.52 |

Figure 5 inspects the accuracy of the RGRC-GODSAE method in the training and validation on 80:20 of TRP/TSP. The result specified that the RGRC-GODSAE technique has greater accuracy values over higher epochs. Also, the greater validation accuracy over training accuracy shows that the RGRC-GODSAE method learns productively on 80:20 of TRP/TSP.

Accuracy curve of RGRC-GODSAE approach on 80:20 of TRP/TSP. Abbreviation: RGRC-GODSAE, robust gesture recognition and classification using growth optimizer with deep stacked autoencoder.
The loss analysis of the RGRC-GODSAE method in training and validation is given on 80:20 of TRP/TSP in Figure 6. The result indicates that the RGRC-GODSAE approach reaches a closer value of training and validation loss. The RGRC-GODSAE method learns productively on 80:20 of TRP/TSP.
Loss curve of RGRC-GODSAE approach on 80:20 of TRP/TSP. Abbreviation: RGRC-GODSAE, robust gesture recognition and classification using growth optimizer with deep stacked autoencoder.
The detailed precision–recall (PR) curve of the RGRC-GODSAE technique is demonstrated on 80:20 of TRP/TSP in Figure 7. The figure states that the RGRC-GODSAE approach has increasing values of PR. Furthermore, the RGRC-GODSAE technique can reach higher PR values in all classes.
PR curve of RGRC-GODSAE approach on 80:20 of TRP/TSP. Abbreviations: PR, precision–recall; RGRC-GODSAE, robust gesture recognition and classification using growth optimizer with deep stacked autoencoder.
In Figure 8, a receiver operating characteristic (ROC) study of the RGRC-GODSAE technique is revealed on 80:20 of TRP/TSP. The figure describes that the RGRC-GODSAE method resulted in better ROC values. Besides, the RGRC-GODSAE technique can extend enhanced ROC values on all classes.
ROC curve of RGRC-GODSAE approach on 80:20 of TRP/TSP. Abbreviations: RGRC-GODSAE, robust gesture recognition and classification using growth optimizer with deep stacked autoencoder; ROC, receiver operating characteristic.
In Table 3 and Figure 9, the gesture recognition outcomes of the RGRC-GODSAE method under 70:30 of TRP/TSP are reported. The experimental values recognize that the RGRC-GODSAE technique accurately detects all the classes. For example, on 70% of TRP, the RGRC-GODSAE method attains an average accu y of 98.48%, prec n of 93.89%, recall of 93.95%, F score of 93.91%, and G measure of 93.92%. In addition, on 30% of TSP, the RGRC-GODSAE technique attains an average accu y of 98.54%, prec n of 94.42%, recall of 94.17%, F score of 94.26%, and G measure of 94.28%.
Gesture recognition outcome of RGRC-GODSAE approach on 70:30 of TRP/TSP.
| Class | Accuracy | Precision | Recall | F-Score | G-Measure |
|---|---|---|---|---|---|
| Training phase (70%) | |||||
| Wrist watch (Cl-1) | 98.39 | 92.48 | 93.89 | 93.18 | 93.18 |
| Dog (Cl-2) | 98.57 | 92.81 | 95.56 | 94.16 | 94.17 |
| Stop sign (Cl-3) | 98.66 | 95.04 | 94.37 | 94.70 | 94.70 |
| Person (Cl-4) | 98.75 | 94.29 | 95.65 | 94.96 | 94.97 |
| Stairs (Cl-5) | 98.04 | 91.30 | 92.65 | 91.97 | 91.97 |
| Chair (Cl-6) | 98.66 | 97.28 | 92.86 | 95.02 | 95.04 |
| Table (Cl-7) | 98.39 | 92.86 | 94.20 | 93.53 | 93.53 |
| Washroom (Cl-8) | 98.39 | 95.07 | 92.47 | 93.75 | 93.76 |
| Average | 98.48 | 93.89 | 93.95 | 93.91 | 93.92 |
| Testing phase (30%) | |||||
| Wrist watch (Cl-1) | 97.92 | 91.55 | 94.20 | 92.86 | 92.87 |
| Dog (Cl-2) | 98.96 | 96.88 | 95.38 | 96.12 | 96.13 |
| Stop sign (Cl-3) | 98.33 | 90.32 | 96.55 | 93.33 | 93.39 |
| Person (Cl-4) | 98.75 | 93.75 | 96.77 | 95.24 | 95.25 |
| Stairs (Cl-5) | 97.50 | 90.62 | 90.62 | 90.62 | 90.62 |
| Chair (Cl-6) | 99.17 | 97.73 | 93.48 | 95.56 | 95.58 |
| Table (Cl-7) | 98.75 | 98.28 | 91.94 | 95.00 | 95.05 |
| Washroom (Cl-8) | 98.96 | 96.23 | 94.44 | 95.33 | 95.33 |
| Average | 98.54 | 94.42 | 94.17 | 94.26 | 94.28 |
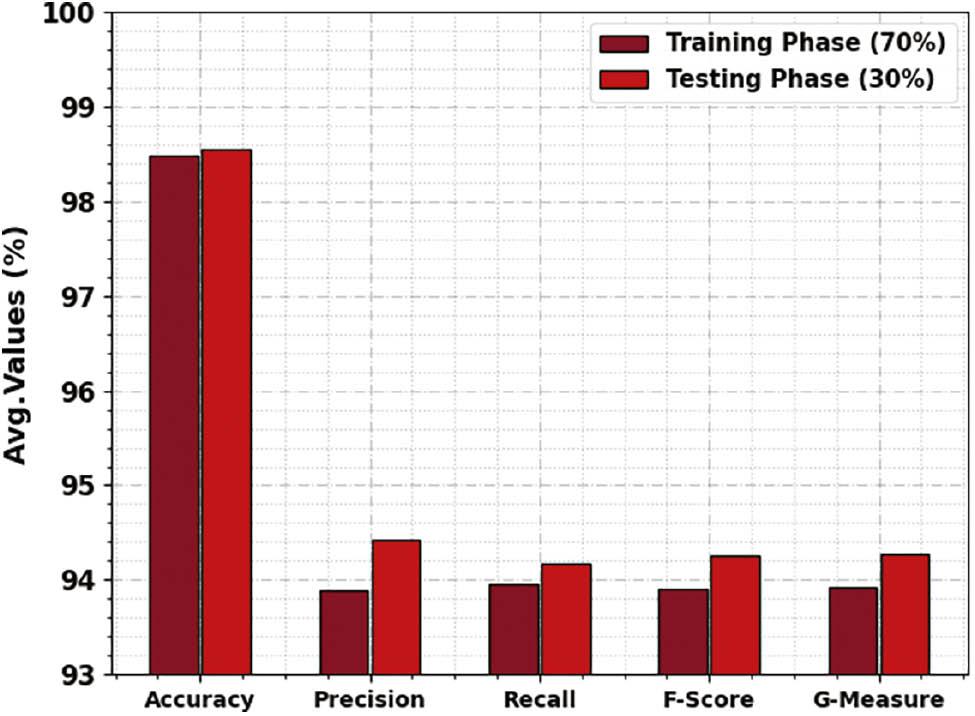
Average outcome of RGRC-GODSAE approach on 70:30 of TRP/TSP. Abbreviation: RGRC-GODSAE, robust gesture recognition and classification using growth optimizer with deep stacked autoencoder.
Figure 10 depicts the accuracy of the RGRC-GODSAE algorithm in the training and validation on 70:30 of TRP/TSP. The result portrays that the RGRC-GODSAE technique attains greater accuracy values over higher epochs. Furthermore, the greater validation accuracy over training accuracy specified that the RGRC-GODSAE method learns productively on 70:30 of TRP/TSP.

Accuracy curve of RGRC-GODSAE method on 70:30 of TRP/TSP. Abbreviation: RGRC-GODSAE, robust gesture recognition and classification using growth optimizer with deep stacked autoencoder.
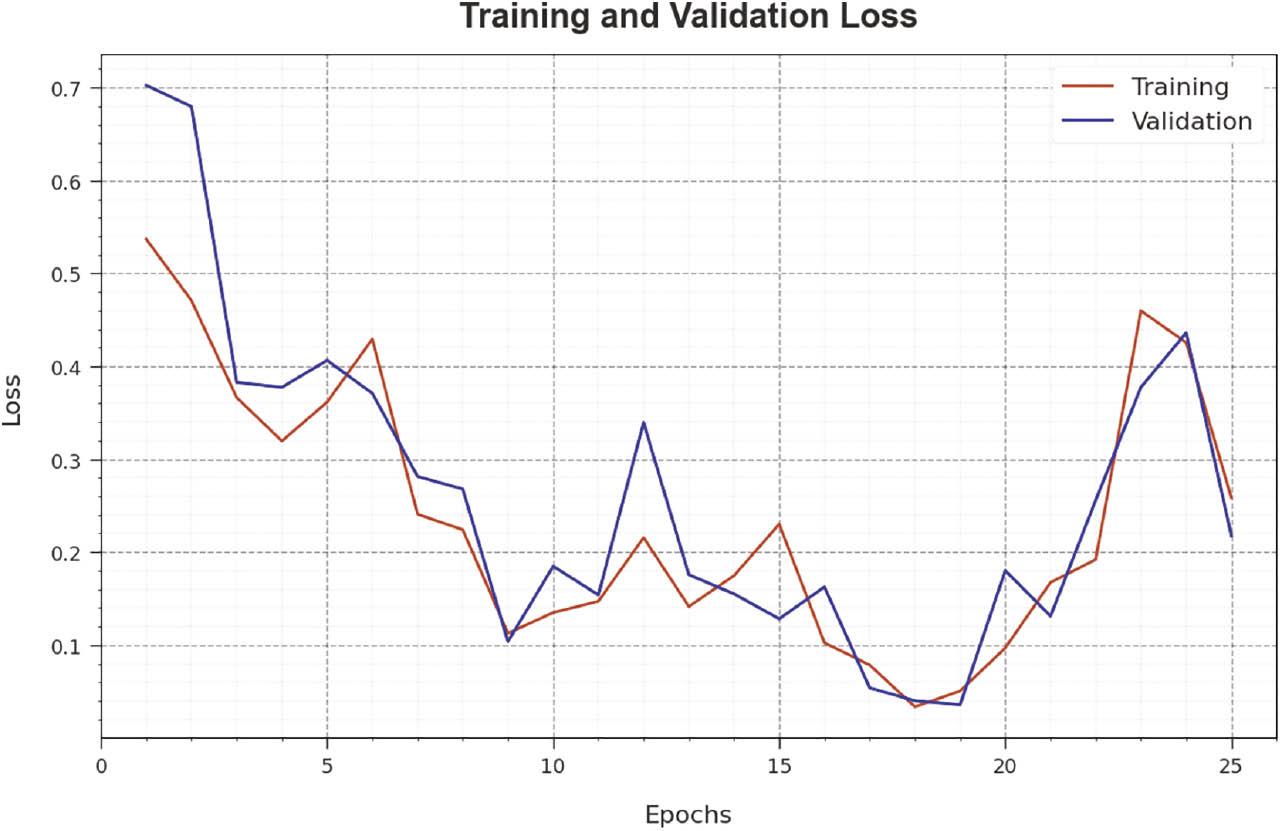
The loss analysis of the RGRC-GODSAE method in training and validation is given on 70:30 of TRP/TSP in Figure 11. The outcomes indicate that the RGRC-GODSAE method reaches a closer value of training and validation loss. The RGRC-GODSAE technique learns productively at 70:30 of TRP/TSP.
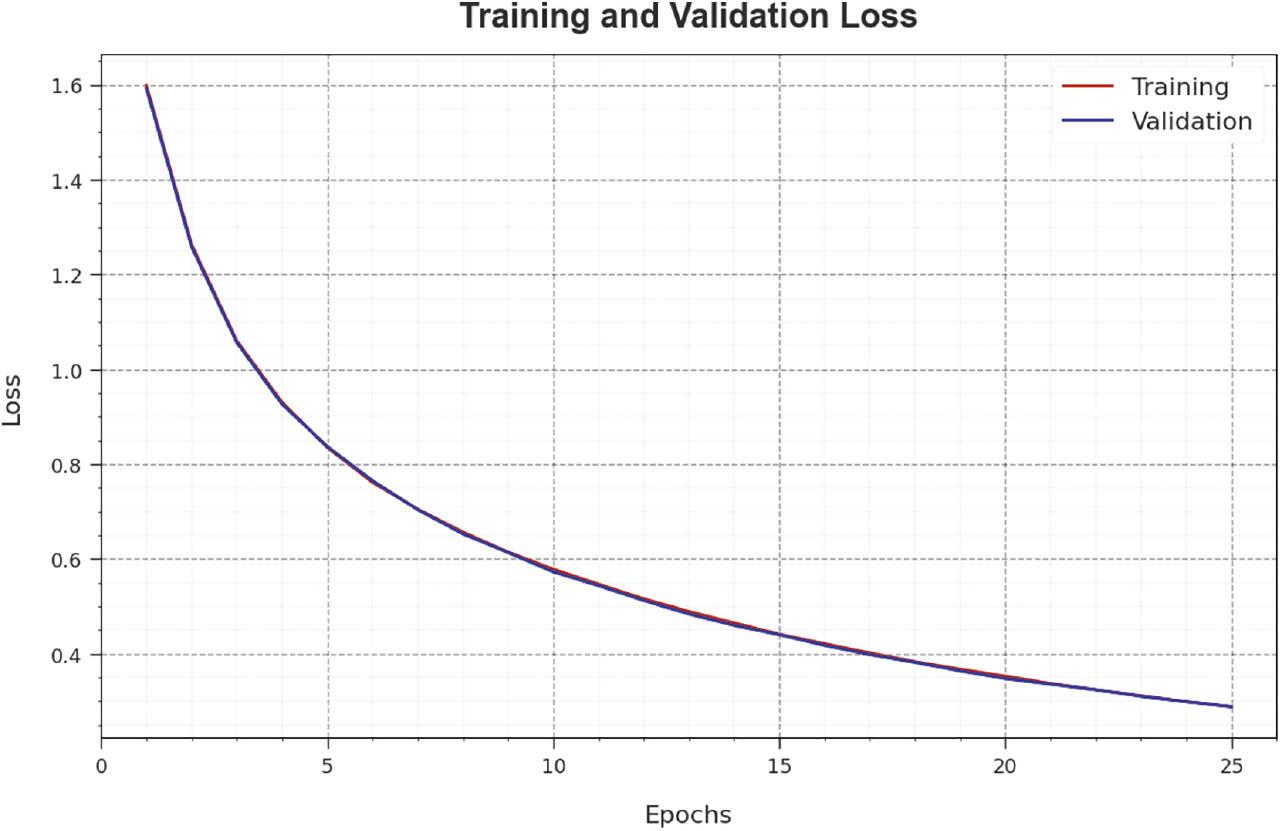
Loss curve of RGRC-GODSAE approach on 70:30 of TRP/TSP. Abbreviation: RGRC-GODSAE, robust gesture recognition and classification using growth optimizer with deep stacked autoencoder.
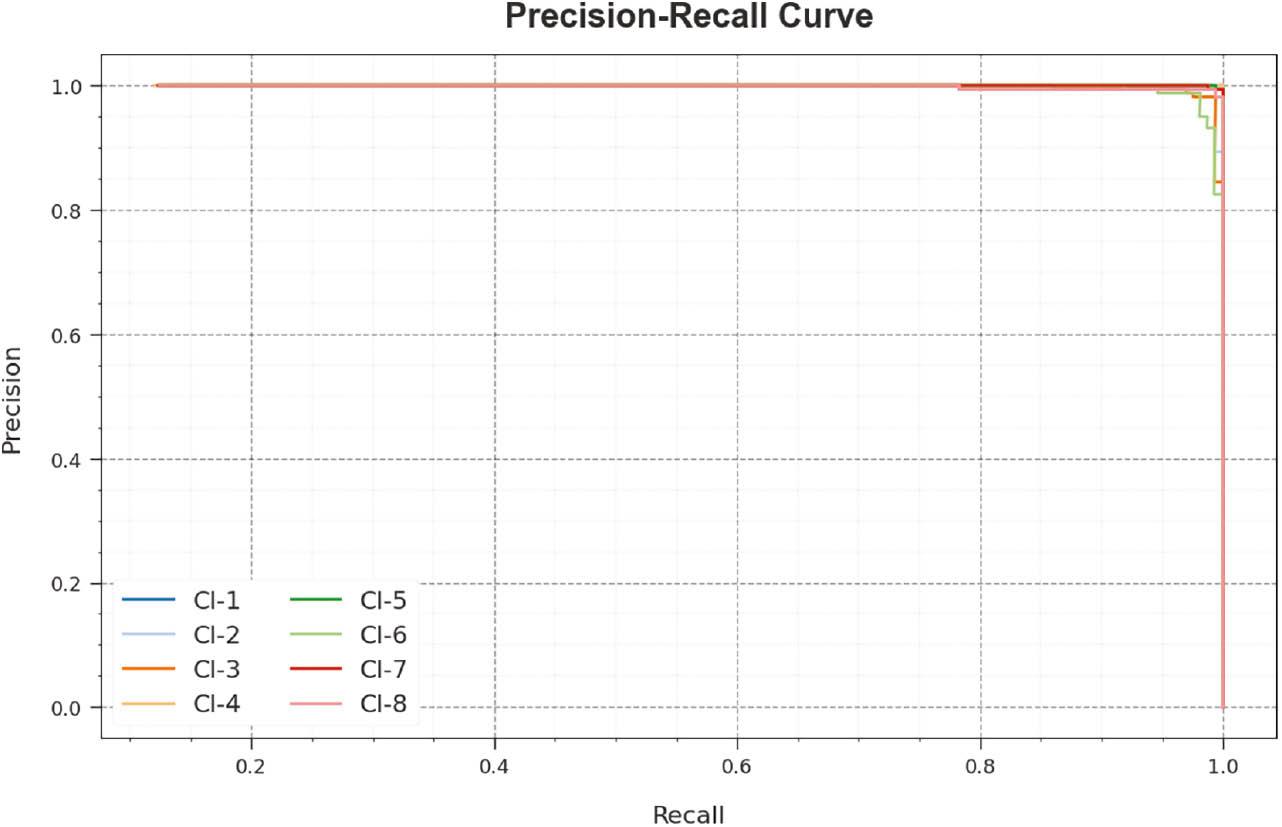
A brief PR curve of the RGRC-GODSAE technique is demonstrated on 70:30 of TRP/TSP in Figure 12. The figure states that the RGRC-GODSAE technique results in increasing values of PR. In addition, the RGRC-GODSAE technique can reach higher PR values in all classes.
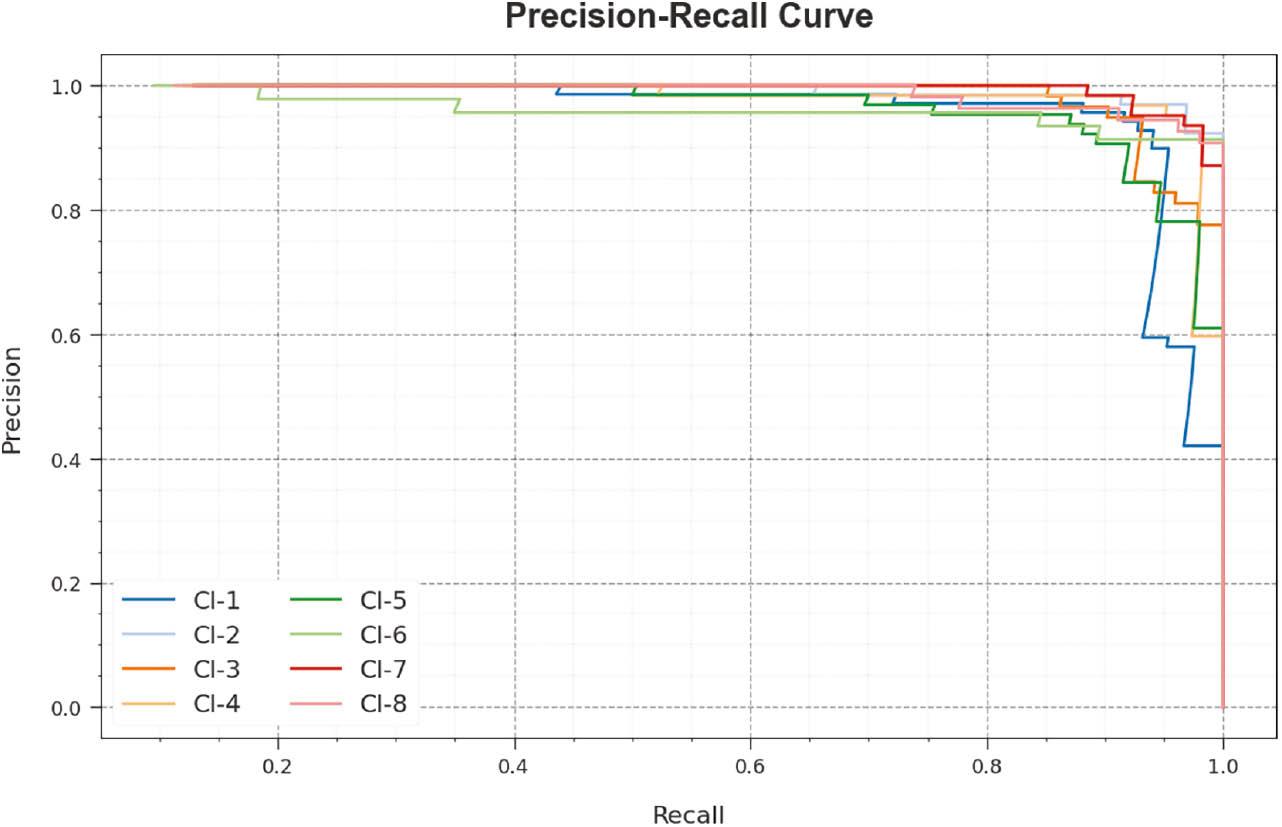
PR curve of RGRC-GODSAE approach on 70:30 of TRP/TSP. Abbreviations: PR, precision–recall; RGRC-GODSAE, robust gesture recognition and classification using growth optimizer with deep stacked autoencoder.
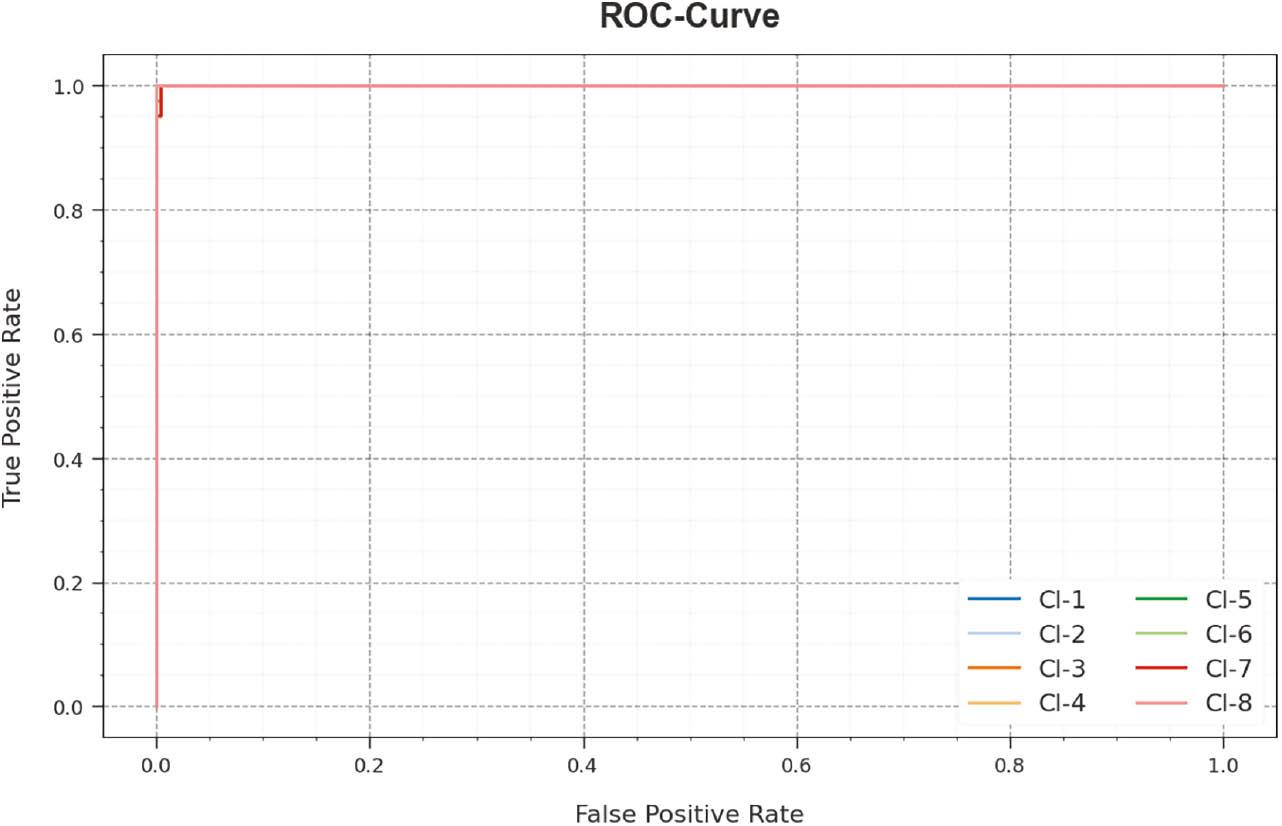
In Figure 13, an ROC study of the RGRC-GODSAE technique is revealed at 70:30 of TRP/TSP. The figure describes that the RGRC-GODSAE approach resulted in improved ROC values. Besides, the RGRC-GODSAE algorithm can extend enhanced ROC values on all classes.
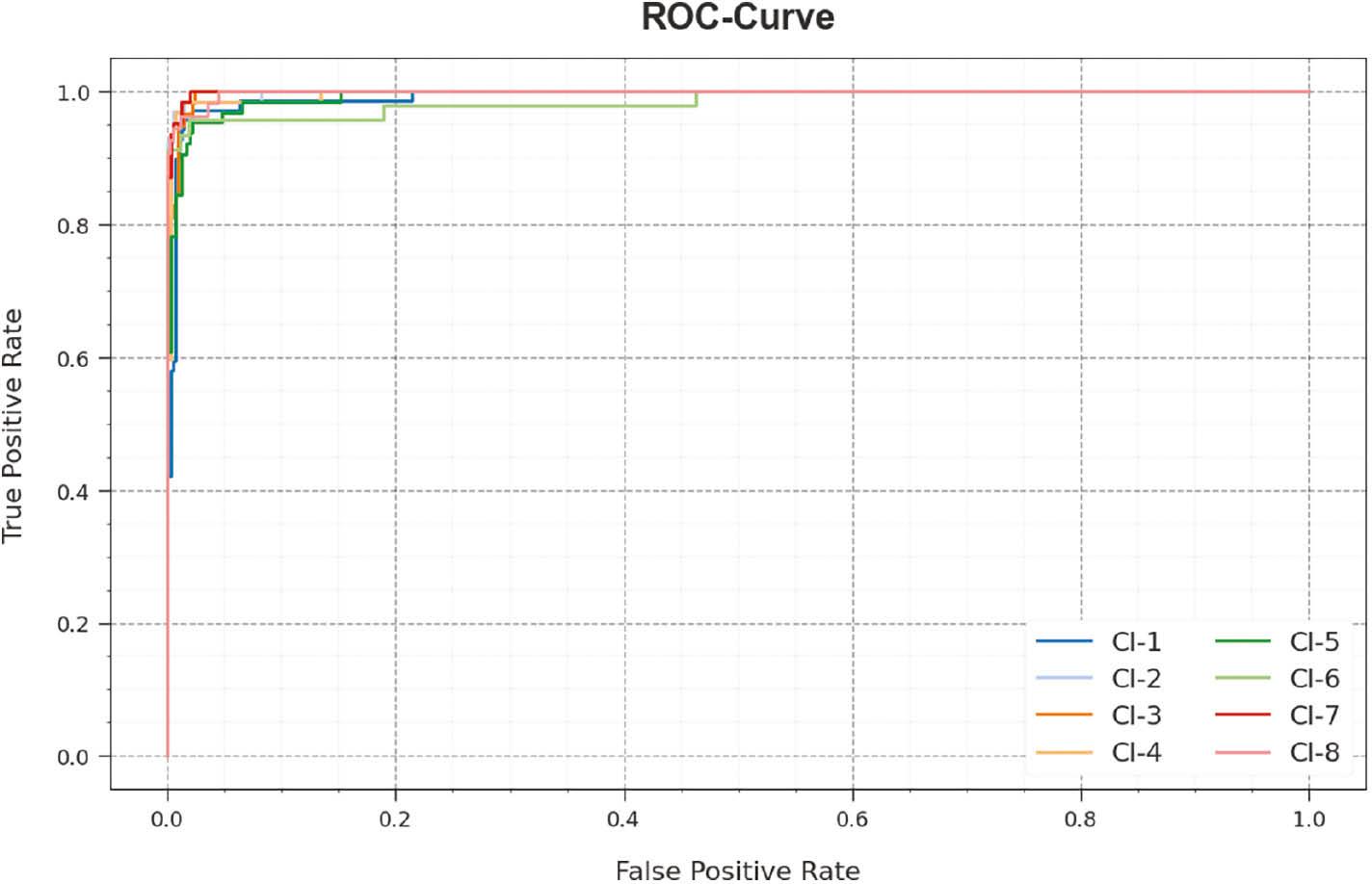
ROC curve of RGRC-GODSAE approach on 70:30 of TRP/TSP. Abbreviations: RGRC-GODSAE, robust gesture recognition and classification using growth optimizer with deep stacked autoencoder; ROC, receiver operating characteristic.
Finally, a comparison study of the RGRC-GODSAE technique with recent approaches in terms of different measures is given in Table 4 and Figure 14 ( Alduhayyem et al., 2023). The experimental values identified that the AlexNet, VGG-16, VGG-19, and GoogleNet models accomplish poor performance over other compared methods. At the same time, the YOLO-v3 model gains slightly enhanced results.

Comparative outcome of RGRC-GODSAE algorithm with other methods. Abbreviation: RGRC-GODSAE, robust gesture recognition and classification using growth optimizer with deep stacked autoencoder.
Comparative outcome of RGRC-GODSAE algorithm with other methods.
| Methods | Accuracy | Precision | Recall | F-Score |
|---|---|---|---|---|
| RGRC-GODSAE | 99.77 | 99.08 | 99.06 | 99.07 |
| TSOLWR-ODVIP | 99.29 | 98.80 | 98.70 | 98.74 |
| SSD-MobileNet | 98.85 | 98.33 | 98.17 | 98.38 |
| YOLO-V3 | 95.55 | 95.16 | 95.77 | 95.80 |
| AlexNet | 85.89 | 86.54 | 84.81 | 89.53 |
| VGG-16 | 86.50 | 85.70 | 87.92 | 89.11 |
| VGG-19 | 84.43 | 84.06 | 87.33 | 87.22 |
| GoogleNet | 88.77 | 86.80 | 89.05 | 86.66 |
Along with that, the TSOLWR-ODVIP and SSD-MobileNet models achieve moderately improved performance. However, the RGRC-GODSAE technique reaches outperforming results with a maximum accu y of 99.77%, prec n of 99.08%, reca l of 99.06%, and F score of 99.07%. These results show the betterment of the RGRC-GODSAE technique over other current methods.
CONCLUSION
In this study, we have introduced a new RGRC-GODSAE technique for effectual recognition and classification of gestures to aid visually impaired persons. The main aim of the RGRC-GODSAE technique lies in the accurate recognition and classification of gestures to assist visually impaired persons. The RGRC-GODSAE technique comprises several subprocesses, namely, GF-based noise elimination, ShuffleNet feature extractor, GO-based hyperparameter tuning, and DSAE-based gesture recognition. The design of the GO algorithm helps in optimal selection of the hyperparameters related to the ShuffleNet model. The experimental outcomes of the RGRC-GODSAE method take place on the benchmark dataset. The extensive comparison study showed the better gesture recognition performance of the RGRC-GODSAE technique over other DL models. In future, the gesture recognition rate of the RGRC-GODSAE technique can be boosted by advanced DL ensemble classifiers.