- Record: found
- Abstract: found
- Article: found
Improving broad-coverage medical entity linking with semantic type prediction and large-scale datasets
Read this article at
Abstract
Objectives:
Biomedical natural language processing tools are increasingly being applied for broad-coverage information extraction—extracting medical information of all types in a scientific document or a clinical note. In such broad-coverage settings, linking mentions of medical concepts to standardized vocabularies requires choosing the best candidate concepts from large inventories covering dozens of types. This study presents a novel semantic type prediction module for biomedical NLP pipelines and two automatically-constructed, large-scale datasets with broad coverage of semantic types.
Methods:
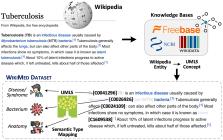
We experiment with five off-the-shelf biomedical NLP toolkits on four benchmark datasets for medical information extraction from scientific literature and clinical notes. All toolkits adopt a staged approach of mention detection followed by two stages of medical entity linking: (1) generating a list of candidate concepts, and (2) picking the best concept among them. We introduce a semantic type prediction module to alleviate the problem of overgeneration of candidate concepts by filtering out irrelevant candidate concepts based on the predicted semantic type of a mention. We present M edT ype, a fully modular semantic type prediction model which we integrate into the existing NLP toolkits. To address the dearth of broad-coverage training data for medical information extraction, we further present W ikiM ed and P ubM edDS, two large-scale datasets for medical entity linking.
Related collections
Most cited references136
- Record: found
- Abstract: not found
- Article: not found
ImageNet Large Scale Visual Recognition Challenge
- Record: found
- Abstract: found
- Article: not found
Adam: A Method for Stochastic Optimization
- Record: found
- Abstract: found
- Article: not found