- Record: found
- Abstract: found
- Article: found
Nitric oxide signaling in ctenophores
Read this article at
Abstract
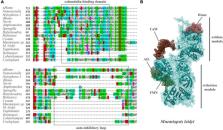
Nitric oxide (NO) is one of the most ancient and versatile signal molecules across all domains of life. NO signaling might also play an essential role in the origin of animal organization. Yet, practically nothing is known about the distribution and functions of NO-dependent signaling pathways in representatives of early branching metazoans such as Ctenophora. Here, we explore the presence and organization of NO signaling components using Mnemiopsis and kin as essential reference species. We show that NO synthase (NOS) is present in at least eight ctenophore species, including Euplokamis and Coeloplana, representing the most basal ctenophore lineages. However, NOS could be secondarily lost in many other ctenophores, including Pleurobrachia and Beroe. In Mnemiopsis leidyi, NOS is present both in adult tissues and differentially expressed in later embryonic stages suggesting the involvement of NO in developmental mechanisms. Ctenophores also possess soluble guanylyl cyclases as potential NO receptors with weak but differential expression across tissues. Combined, these data indicate that the canonical NO-cGMP signaling pathways existed in the common ancestor of animals and could be involved in the control of morphogenesis, cilia activities, feeding and different behaviors.
Related collections
Most cited references97

- Record: found
- Abstract: found
- Article: found
Highly accurate protein structure prediction with AlphaFold

- Record: found
- Abstract: found
- Article: found
SWISS-MODEL: homology modelling of protein structures and complexes
- Record: found
- Abstract: found
- Article: not found