- Record: found
- Abstract: found
- Article: not found
Laryngeal Pressure Estimation With a Recurrent Neural Network

Read this article at

Abstract
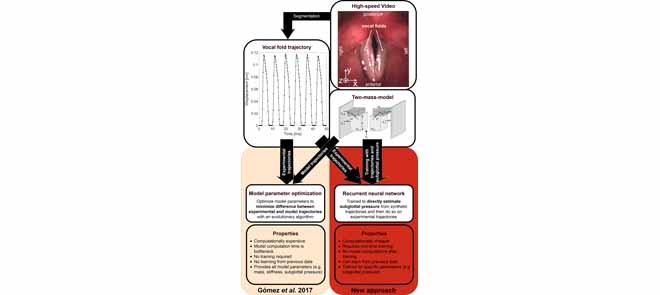
Quantifying the physical parameters of voice production is essential for understanding the process of phonation and can aid in voice research and diagnosis. As an alternative to invasive measurements, they can be estimated by formulating an inverse problem using a numerical forward model. However, high-fidelity numerical models are often computationally too expensive for this. This paper presents a novel approach to train a long short-term memory network to estimate the subglottal pressure in the larynx at massively reduced computational cost using solely synthetic training data. We train the network on synthetic data from a numerical two-mass model and validate it on experimental data from 288 high-speed ex vivo video recordings of porcine vocal folds from a previous study. The training requires significantly fewer model evaluations compared with the previous optimization approach. On the test set, we maintain a comparable performance of 21.2% versus previous 17.7% mean absolute percentage error in estimating the subglottal pressure. The evaluation of one sample requires a vanishingly small amount of computation time. The presented approach is able to maintain estimation accuracy of the subglottal pressure at significantly reduced computational cost. The methodology is likely transferable to estimate other parameters and training with other numerical models. This improvement should allow the adoption of more sophisticated, high-fidelity numerical models of the larynx. The vast speedup is a critical step to enable a future clinical application and knowledge of parameters such as the subglottal pressure will aid in diagnosis and treatment selection.
Abstract
Related collections
Most cited references47
- Record: found
- Abstract: found
- Article: not found
Reynolds averaged turbulence modelling using deep neural networks with embedded invariance
- Record: found
- Abstract: found
- Article: found
Deep Convolutional Neural Networks for Computer-Aided Detection: CNN Architectures, Dataset Characteristics and Transfer Learning
- Record: found
- Abstract: not found
- Article: not found