- Record: found
- Abstract: found
- Article: found
Modeling functional changes to Escherichia coli thymidylate synthase upon single residue replacements: a structure-based approach
Read this article at
Abstract
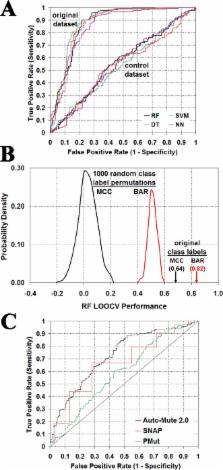
Escherichia coli thymidylate synthase (TS) is an enzyme that is indispensable to DNA synthesis and cell division, as it provides the only de novo source of dTMP by catalyzing the reductive methylation of dUMP, thus making it a key target for chemotherapeutic agents. High resolution X-ray crystallographic structures are available for TS and, owing to its relatively small size, successful experimental mutagenesis studies have been conducted on the enzyme. In this study, an in silico mutagenesis technique is used to investigate the effects of single amino acid substitutions in TS on enzymatic activity, one that employs the TS protein structure as well as a knowledge-based, four-body statistical potential. For every single residue TS variant, this approach yields both a global structural perturbation score and a set of local environmental perturbation scores that characterize the mutated position as well as all structurally neighboring residues. Global scores for the TS variants are capable of uniquely characterizing groups of residue positions in the enzyme according to their physicochemical, functional, or structural properties. Additionally, these global scores elucidate a statistically significant structure–function relationship among a collection of 372 single residue TS variants whose activity levels have been experimentally determined. Predictive models of TS variant activity are subsequently trained on this dataset of experimental mutants, whose respective feature vectors encode information regarding the mutated position as well as its six nearest residue neighbors in the TS structure, including their environmental perturbation scores.
Related collections
Most cited references47
- Record: found
- Abstract: found
- Article: not found
The meaning and use of the area under a receiver operating characteristic (ROC) curve.
- Record: found
- Abstract: found
- Article: not found