- Record: found
- Abstract: found
- Article: found
Intrinsically-disordered N-termini in human parechovirus 1 capsid proteins bind encapsidated RNA
Read this article at
Abstract
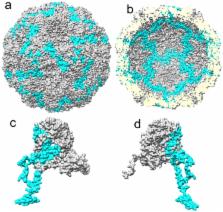
Human parechoviruses (HPeV) are picornaviruses with a highly-ordered RNA genome contained within icosahedrally-symmetric capsids. Ordered RNA structures have recently been shown to interact with capsid proteins VP1 and VP3 and facilitate virus assembly in HPeV1. Using an assay that combines reversible cross-linking, RNA affinity purification and peptide mass fingerprinting (RCAP), we mapped the RNA-interacting regions of the capsid proteins from the whole HPeV1 virion in solution. The intrinsically-disordered N-termini of capsid proteins VP1 and VP3, and unexpectedly, VP0, were identified to interact with RNA. Comparing these results to those obtained using recombinantly-expressed VP0 and VP1 confirmed the virion binding regions, and revealed unique RNA binding regions in the isolated VP0 not previously observed in the crystal structure of HPeV1. We used RNA fluorescence anisotropy to confirm the RNA-binding competency of each of the capsid proteins’ N-termini. These findings suggests that dynamic interactions between the viral RNA and the capsid proteins modulate virus assembly, and suggest a novel role for VP0.
Related collections
Most cited references32
- Record: found
- Abstract: found
- Article: not found
The CRAPome: a Contaminant Repository for Affinity Purification Mass Spectrometry Data
- Record: found
- Abstract: found
- Article: not found
Sequence complexity of disordered protein.
- Record: found
- Abstract: not found
- Article: not found