- Record: found
- Abstract: found
- Article: found
Functional assignment of KEOPS/EKC complex subunits in the biosynthesis of the universal t 6A tRNA modification
Read this article at
Abstract
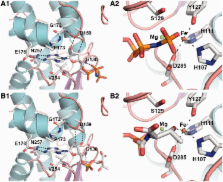
N 6-threonylcarbamoyladenosine (t 6A) is a universal tRNA modification essential for normal cell growth and accurate translation. In Archaea and Eukarya, the universal protein Sua5 and the conserved KEOPS/EKC complex together catalyze t 6A biosynthesis. The KEOPS/EKC complex is composed of Kae1, a universal metalloprotein belonging to the ASHKA superfamily of ATPases; Bud32, an atypical protein kinase and two small proteins, Cgi121 and Pcc1. In this study, we investigated the requirement and functional role of KEOPS/EKC subunits for biosynthesis of t 6A. We demonstrated that Pcc1, Kae1 and Bud32 form a minimal functional unit, whereas Cgi121 acts as an allosteric regulator. We confirmed that Pcc1 promotes dimerization of the KEOPS/EKC complex and uncovered that together with Kae1, it forms the tRNA binding core of the complex. Kae1 binds l-threonyl-carbamoyl-AMP intermediate in a metal-dependent fashion and transfers the l-threonyl-carbamoyl moiety to substrate tRNA. Surprisingly, we found that Bud32 is regulated by Kae1 and does not function as a protein kinase but as a P-loop ATPase possibly involved in tRNA dissociation. Overall, our data support a mechanistic model in which the final step in the biosynthesis of t 6A relies on a strictly catalytic component, Kae1, and three partner proteins necessary for dimerization, tRNA binding and regulation.
Related collections
Most cited references49
- Record: found
- Abstract: found
- Article: found
tRNAdb 2009: compilation of tRNA sequences and tRNA genes

- Record: found
- Abstract: found
- Article: found
PaxDb, a Database of Protein Abundance Averages Across All Three Domains of Life*
- Record: found
- Abstract: found
- Article: not found