- Record: found
- Abstract: found
- Article: found
Sequencing the cap-snatching repertoire of H1N1 influenza provides insight into the mechanism of viral transcription initiation
Read this article at
Abstract
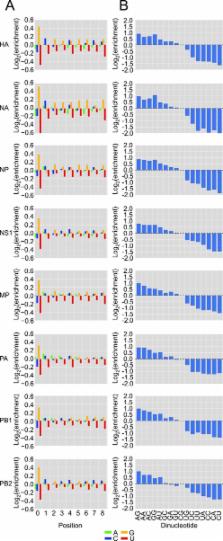
The influenza polymerase cleaves host RNAs ∼10–13 nucleotides downstream of their 5′ ends and uses this capped fragment to prime viral mRNA synthesis. To better understand this process of cap snatching, we used high-throughput sequencing to determine the 5′ ends of A/WSN/33 (H1N1) influenza mRNAs. The sequences provided clear evidence for nascent-chain realignment during transcription initiation and revealed a strong influence of the viral template on the frequency of realignment. After accounting for the extra nucleotides inserted through realignment, analysis of the capped fragments indicated that the different viral mRNAs were each prepended with a common set of sequences and that the polymerase often cleaved host RNAs after a purine and often primed transcription on a single base pair to either the terminal or penultimate residue of the viral template. We also developed a bioinformatic approach to identify the targeted host transcripts despite limited information content within snatched fragments and found that small nuclear RNAs and small nucleolar RNAs contributed the most abundant capped leaders. These results provide insight into the mechanism of viral transcription initiation and reveal the diversity of the cap-snatched repertoire, showing that noncoding transcripts as well as mRNAs are used to make influenza mRNAs.
Related collections
Most cited references59
- Record: found
- Abstract: found
- Article: not found
Counting absolute numbers of molecules using unique molecular identifiers.
- Record: found
- Abstract: found
- Article: not found
The cap-snatching endonuclease of influenza virus polymerase resides in the PA subunit.
- Record: found
- Abstract: found
- Article: not found