- Record: found
- Abstract: found
- Article: not found
Highly Conserved Non-Coding Sequences Are Associated with Vertebrate Development
Read this article at

Abstract
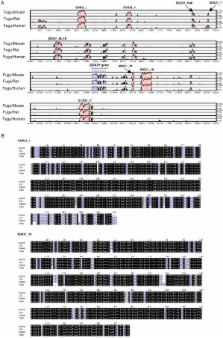
In addition to protein coding sequence, the human genome contains a significant amount of regulatory DNA, the identification of which is proving somewhat recalcitrant to both in silico and functional methods. An approach that has been used with some success is comparative sequence analysis, whereby equivalent genomic regions from different organisms are compared in order to identify both similarities and differences. In general, similarities in sequence between highly divergent organisms imply functional constraint. We have used a whole-genome comparison between humans and the pufferfish, Fugu rubripes, to identify nearly 1,400 highly conserved non-coding sequences. Given the evolutionary divergence between these species, it is likely that these sequences are found in, and furthermore are essential to, all vertebrates. Most, and possibly all, of these sequences are located in and around genes that act as developmental regulators. Some of these sequences are over 90% identical across more than 500 bases, being more highly conserved than coding sequence between these two species. Despite this, we cannot find any similar sequences in invertebrate genomes. In order to begin to functionally test this set of sequences, we have used a rapid in vivo assay system using zebrafish embryos that allows tissue-specific enhancer activity to be identified. Functional data is presented for highly conserved non-coding sequences associated with four unrelated developmental regulators (SOX21, PAX6, HLXB9, and SHH), in order to demonstrate the suitability of this screen to a wide range of genes and expression patterns. Of 25 sequence elements tested around these four genes, 23 show significant enhancer activity in one or more tissues. We have identified a set of non-coding sequences that are highly conserved throughout vertebrates. They are found in clusters across the human genome, principally around genes that are implicated in the regulation of development, including many transcription factors. These highly conserved non-coding sequences are likely to form part of the genomic circuitry that uniquely defines vertebrate development.
Abstract
Highly conserved non-coding sequences in vertebrate genomes are frequently located around genes involved in development and can direct tissue-specific gene expression in functional assays.
Related collections
Most cited references61
- Record: found
- Abstract: found
- Article: not found
Gene Ontology: tool for the unification of biology
- Record: found
- Abstract: found
- Article: not found
Rfam: an RNA family database.
- Record: found
- Abstract: found
- Article: not found