- Record: found
- Abstract: found
- Article: found
FunnyBase: a systems level functional annotation of Fundulus ESTs for the analysis of gene expression
Read this article at
Abstract
Background
While studies of non-model organisms are critical for many research areas, such as evolution, development, and environmental biology, they present particular challenges for both experimental and computational genomic level research. Resources such as mass-produced microarrays and the computational tools linking these data to functional annotation at the system and pathway level are rarely available for non-model species. This type of "systems-level" analysis is critical to the understanding of patterns of gene expression that underlie biological processes.
Results
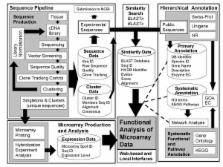
We describe a bioinformatics pipeline known as FunnyBase that has been used to store, annotate, and analyze 40,363 expressed sequence tags (ESTs) from the heart and liver of the fish, Fundulus heteroclitus. Primary annotations based on sequence similarity are linked to networks of systematic annotation in Gene Ontology (GO) and the Kyoto Encyclopedia of Genes and Genomes (KEGG) and can be queried and computationally utilized in downstream analyses. Steps are taken to ensure that the annotation is self-consistent and that the structure of GO is used to identify higher level functions that may not be annotated directly. An integrated framework for cDNA library production, sequencing, quality control, expression data generation, and systems-level analysis is presented and utilized. In a case study, a set of genes, that had statistically significant regression between gene expression levels and environmental temperature along the Atlantic Coast, shows a statistically significant (P < 0.001) enrichment in genes associated with amine metabolism.
Conclusion
The methods described have application for functional genomics studies, particularly among non-model organisms. The web interface for FunnyBase can be accessed at http://genomics.rsmas.miami.edu/funnybase/super_craw4/. Data and source code are available by request at jpaschall@ 123456bioinfobase.umkc.edu .
Related collections
Most cited references50
- Record: found
- Abstract: found
- Article: not found
Gene Ontology: tool for the unification of biology
- Record: found
- Abstract: not found
- Article: not found
Basic Local Alignment Search Tool
- Record: found
- Abstract: found
- Article: not found